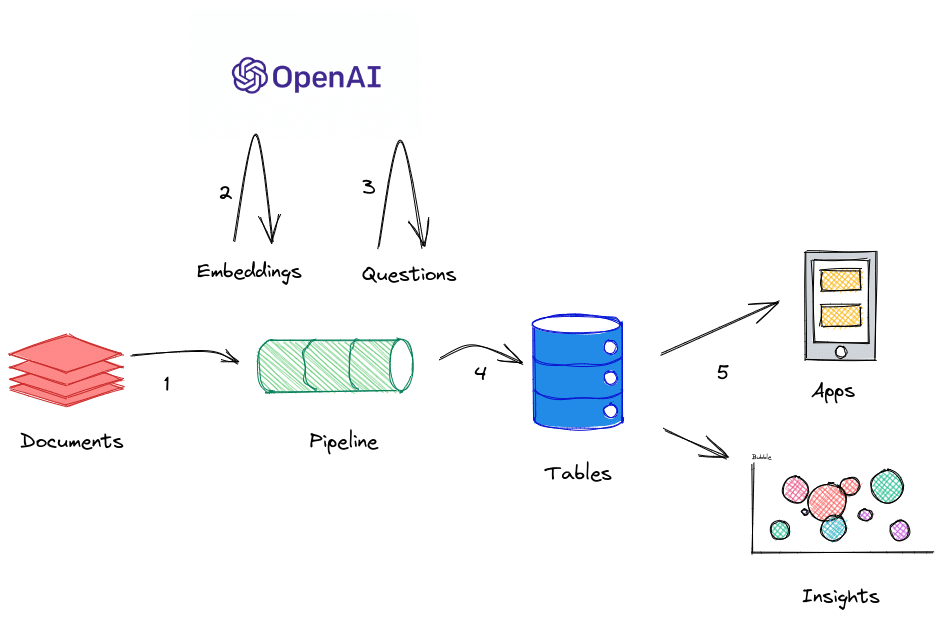
Technology: Using GPT-3 large language model to extract structured information from documents
ChatGPT is driving renewed enthusiasm, and hype, for Artificial Intelligence. In this article, we explore the use of the GPT-3 large language model to extract data from documents via streamlined use of ETL tools.
In plain English: We used AI to read a document and put the answers into a spreadsheet.
Why?
- Millions of documents can be read at the same cost as one human.
- Complex questions can be asked with better-than-human performance reading comprehension.
- Extracting answers to questions into a spreadsheet enables analytics across document dimensions, time for example.
Other potential use cases could include better-than-human performance on data entry, document text extraction, and screen scraping (which requires a human to pinpoint the required data).
Background and terminology
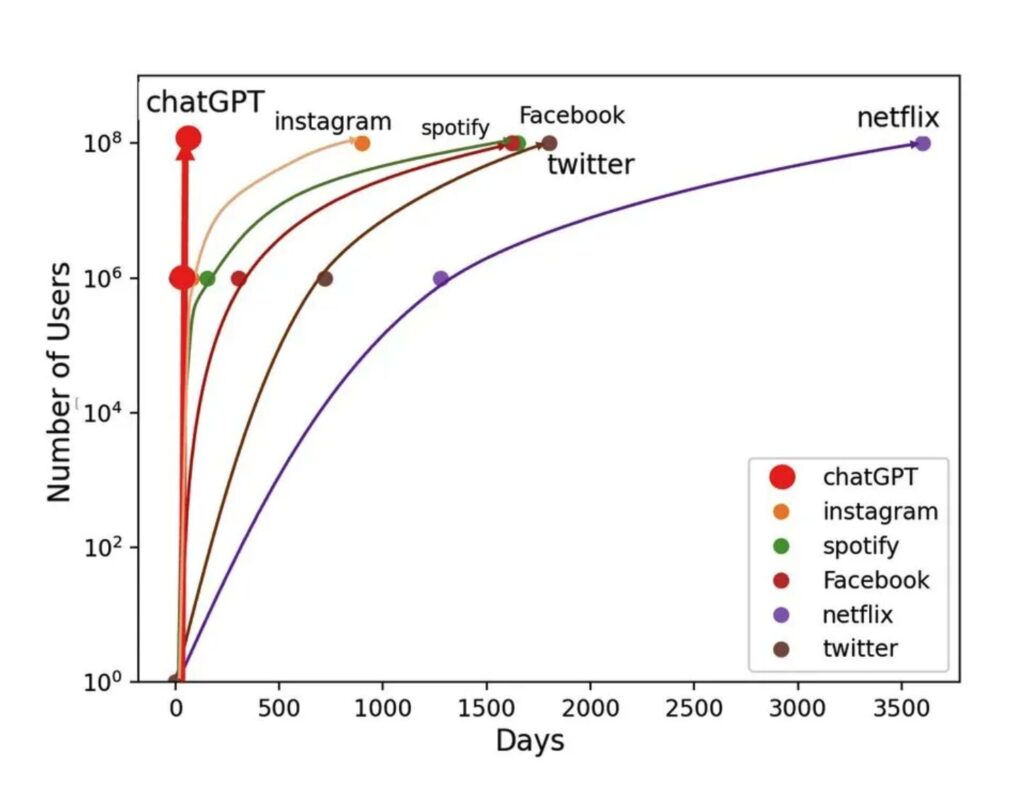
At this time, ChatGPT has the fastest adoption to 100M users in history. GPT-3 is the technology driving this groundbreaking user experience.
What is GPT-3?
GPT-3 is the large language model created by OpenAI and made available through an API.
What is unsupervised question answering?
Unsupervised question answering is the technology description for the ability to answer questions without explicit supervision from human-annotated training data. By contrast, most popular document extraction techniques rely on a human to isolate the text.
What is structured and unstructured data?
Structured data has metrics that can be analysed using dimensions. Spreadsheets are a good example of structured data. Unstructured data has no clearly defined information points or dimensions. Documents, videos, and interviews are good examples of unstructured data.
Overview
Our goal is to gather information about companies and perform analytics on that data. Bear in mind, these techniques could be applied to any domain and any set of documents or questions.
In the UK, companies are required to submit accounts to Companies House with certain information depending on the company size – e.g. Profit and Loss, Balance Sheet, and number of employees. This information is typically submitted by an accountant, each with its own document structure and wording. All company filings are publicly available and depending on the question may be from a structured or unstructured source.
What is the company number?
What is the company name?
What is the company address?
What is the company sector?
What is the filing date?
What are the accounts made up to date?
What are the total assets?
What is the average number of employees?
Analysing data such as employees or assets over time can give very powerful insights that are simply not obvious when presented with only the latest results.
Technology Approach
Companies House data is available through a REST API, as well as bulk downloads (referred to as the Free Company Data Product). Most “useful” information pertaining to performance metrics, like revenue, assets, and the number of employees, is not available as a structured web resource but is tied up in unstructured company filings as a downloadable XHTML or PDF file. The challenge here is to be able to extract data from these unstructured sources.
Solving this question-answering problem at scale requires us to overcome several challenges.
- Dealing with 100’s of gigabytes of documents;
- Identify the text that contains the answer;
- Understand the question context and extract the answer;
- Load the metrics and dimensions into an analytics model;
- Apps and insight can now be powered from this highly structured data;
It is steps 2 & 3 that require heavy lifting and the help of a Large Language Model. The nature of this solution is to first understand the context of a sentence in relation to all other sentences, then second understand the context of the question to identify the answer in the context of the sentence. Something our powerful human brains are capable of without breaking a sweat.
Repeating this document load, embedding, and question answering for each company, and each filing requires a tremendous amount of processing. But once setup, it’s a huge win to be able to repeat the process and tune it – saving months or years of human time and at greater accuracy.
Privacy, cost, and license considerations
Processing data, especially with a web service and AI, has several thorny issues to be considered. The first and most important form many is Data Privacy. As you can see from the diagram above, data is sent to OpenAI and the terms of the service mean that this data can be used by OpenAI. This is unsuitable for any sensitive data – personally identifiable information for example. Other considerations include processing costs, rights to use, and re-publishing restrictions.
Results
5.6M companies were loaded into a Matatika-managed workspace using Meltano. This initial load took around 3 hours with a batch size of 100,000 records.
Using Beautifulsoup, ChromaDB, and a custom GPT extension each Company Filing in XHTML or PDF was processed. The processing cost to download, vectorize, and load structured answers was around 3p per document for our set of questions.
Source code and further notes
- tap-beautifulsoup
- tap-gpt
- Some PDFs were images and needed text extraction before processing using OCRmyPDF
- We used ChromaDB (a database based on DuckDB) to store and search vectorised text. Postgres does have vector data type support, and Matatika workspaces can also leverage Elasticsearch text vectors
- Once the text content was vectorised, tap-gpt was used to query the data using natural language in the form of plain English questions. The result was output from the tap in a CSV structure, which meant we were able to pipe the structured results to any Matatika-supported target.
This whole process was encapsulated into a single script that uses the Companies House API and runs the relevant Meltano commands as subprocesses.
For more information on ETL Tools, see our in-depth piece: Ultimate Guide to ETL Tools for Modern Business Intelligence

Connect to Apps & Data now
Use Matatika to rapidly produce insights from more than 500+ apps and community sources

Data Leaders Digest
Stay up to date with the latest news and insights for data leaders.